Python
[Pandas]데이터 분석하기
zzheng
2024. 6. 12. 21:29
파이썬의 판다스 라이브러리를 사용하여 데이터를 확인해보겠습니다.
이를 위해, 먼저 데이터를 다운 받아보겠습니다. 아래의 사이트에 이동해서 데이터를 다운받아서 알집을 풀어준 후, 원하시는 경로에 저장하면 됩니다. 아래 데이터는 의료데이터 입니다.
https://physionet.org/content/mimiciii-demo/1.4/#files-panel
MIMIC-III Clinical Database Demo v1.4
physionet.org
그다음, 먼저 판다스를 import합니다.
import pandas as pdPATH에 데이터를 저장한 경로를 작성한 다음, 아래와 같이 데이터프레임으로 불러옵니다.
PATH = '/content/drive/MyDrive/data/mimic-iii-clinical-database-demo-1.4/'
patients = pd.read_csv(PATH+"PATIENTS.csv" )
admissions = pd.read_csv(PATH+"ADMISSIONS.csv" )
diagnoses_icd = pd.read_csv(PATH+"DIAGNOSES_ICD.csv" )
icustays = pd.read_csv(PATH+"ICUSTAYS.csv" )
d_icd_diagnoses = pd.read_csv(PATH+"D_ICD_DIAGNOSES.csv" )
chartevents = pd.read_csv(PATH+"CHARTEVENTS.csv" )이제 판다스를 이용해서 데이터를 분석해보겠습니다.
- 정보보기
patients.info()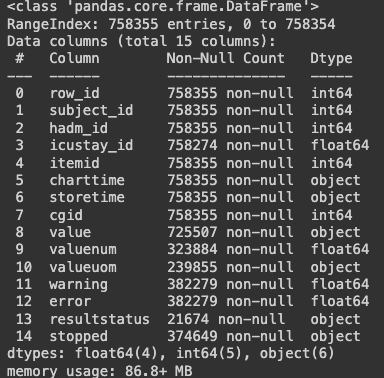
patients.nunique()
patients.gender.value_counts()
patients.subject_id
- patients 테이블 정보 확인 및 부분 정보 추출
patients.loc[:, 'subject_id':'dob']
- 질환명 데이블 정보 확인
diagnoses_icd.info()
diagnoses_icd.columns
d_icd_diagnoses.info()
- 환자의 진단명 알아보기
pd.merge(diagnoses_icd, d_icd_diagnoses, on='icd9_code', how='left')
df1 =pd.merge(diagnoses_icd, d_icd_diagnoses, on='icd9_code', how='left')[['subject_id', 'hadm_id', 'seq_num', 'icd9_code', 'short_title']]
df1
- 어느 진단명의 환자가 많았을까?
df1.short_title.value_counts()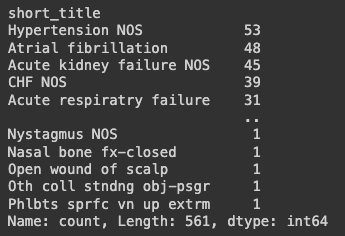
- 20개정도 보기
df1.short_title.value_counts()[:20]
- 각 환자는 몇 번씩 입원했나?
g = df1.groupby(['subject_id'])
g.count()
g.hadm_id.count()
- 환자별로 입원시 진단명 확인
for p_id, df in g:
print(f'subject_id: {p_id}')
print(df.short_title.values)
print()
- 환자 정보 중 성별 정보와 입원 정보 추출
d2 = pd.merge(patients, admissions, on='subject_id', how='left')
d2 = d2[['subject_id', 'gender', 'hadm_id', 'insurance', 'diagnosis', \
'admittime', 'admission_type', 'admission_location']]
d2
- 환자는 어떻게 입원했는가? 보험은?
d2.admission_type.value_counts()
d2.insurance.value_counts()
- 각 보험별로 질환별 환자는 몇 명인가?
d2.groupby(['insurance', 'diagnosis']).count()
- 어떤 보험의 어떤 질환이 가장 많았을까?
d2.groupby(['insurance', 'diagnosis']).subject_id.count()
d2.groupby(by=['insurance', 'diagnosis']).count().index[0:2]
d2.groupby(['insurance', 'diagnosis']).subject_id.count().max()
d2.groupby(['insurance', 'diagnosis']).subject_id.count().argmax()
d2.groupby(by=['insurance', 'diagnosis']).count().index[61]
- 환자의 집중치료실 입원정보
#환자 정보를 집중치료실 입원정보와 결합
d3 = pd.merge(d2, icustays, on=['subject_id', 'hadm_id'])
d3
d3.subject_id.value_counts()
- 환자별 집중치료실 입원횟수와 입퇴원 날짜 시간 알아보기
g = d3.groupby('subject_id')for p_id, df in g:
print(f'subject_id: {p_id} ({len(df)}회')
print(df[['first_wardid', 'last_wardid', 'intime', 'outtime']])
print()
for p_id, df in g:
print(f'subject_id: {p_id} ({len(df)}회')
print(df[['icustay_id','first_wardid', 'last_wardid', 'intime', 'outtime']])
print('-'*70)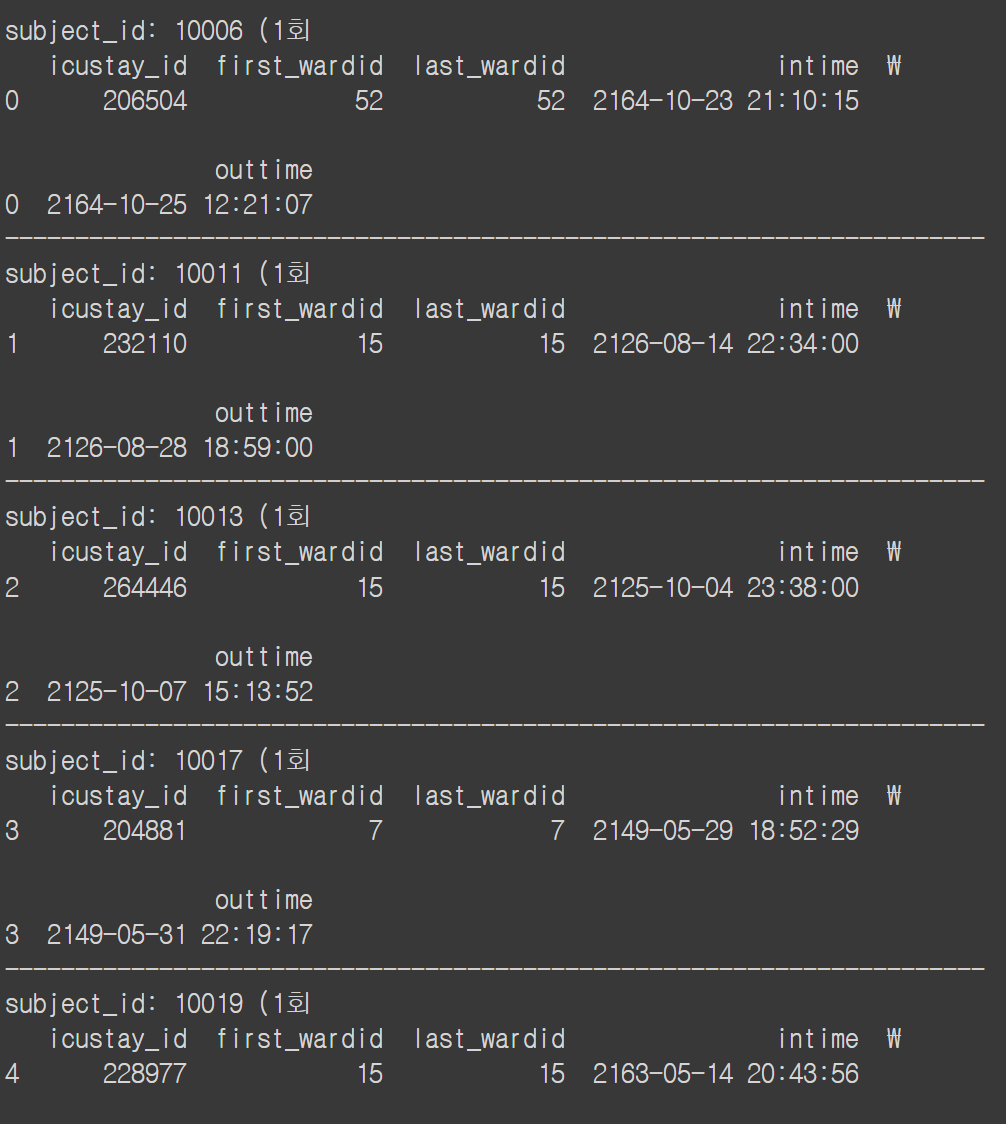
d3[d3.subject_id ==41976][['icustay_id', 'first_wardid', 'last_wardid', 'intime', 'outtime']]
- 질환별로 집중치료실 사용상태 알아보기
d3.columns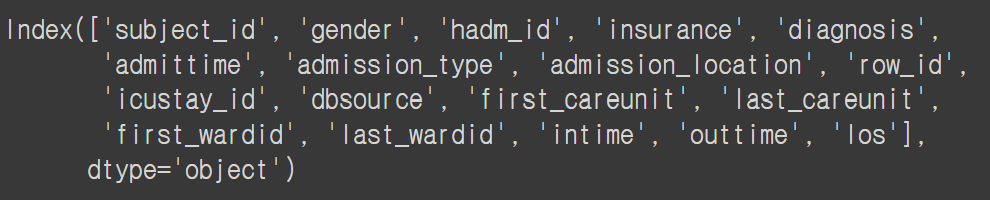
g = d3.groupby('diagnosis')
g.count().subject_id.value_counts()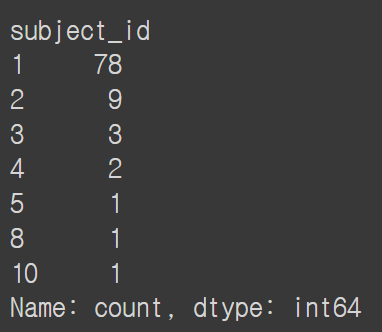
for d_id, df in g:
print(f'질환명: {d_id} ({len(df)}회')
print(df[['subject_id', 'intime', 'outtime']])
print('-'*70)