데이터 스케일링(Data Scaling)은 데이터의 범위와 분포를 일정한 기준에 맞추어 조정하는 과정입니다. 이는 머신러닝 모델의 성능과 학습 속도를 향상시키기 위해 중요한 전처리 단계입니다. 데이터 스케일링은 주로 다음과 같은 두 가지 방법으로 수행됩니다:
- 표준화(Standardization)
- 정규화(Normalization)
왜 데이터 스케일링이 필요한가?
- 특성의 중요도 균형: 특성 간의 범위 차이가 큰 경우, 범위가 큰 특성이 모델에 더 큰 영향을 미치게 됩니다. 스케일링을 통해 이 문제를 완화할 수 있습니다.
- 학습 속도 향상: 스케일링된 데이터는 경사 하강법과 같은 최적화 알고리즘의 수렴 속도를 높여 학습 속도를 향상시킵니다.
- 수렴 안정성: 데이터의 스케일 차이가 크면 학습 과정에서 수렴이 불안정해질 수 있습니다. 스케일링을 통해 수렴 과정을 안정시킬 수 있습니다.
표준화 (Standardization)
표준화는 데이터의 평균을 0, 표준편차를 1로 맞추는 방법입니다. 이를 통해 데이터가 평균을 중심으로 정규 분포를 따르도록 합니다. 표준화는 다음 공식을 사용합니다:
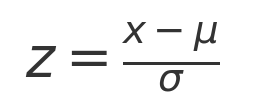
이는 데이터 x가 평균 μ와 표준편차 σ를 기준으로 얼마나 떨어져 있는지를 나타내는 표준 점수(z-score)를 계산합니다.
장점
- 데이터의 분포가 평균을 중심으로 균등하게 퍼지게 되어 모델이 각 특성을 균형 있게 학습할 수 있습니다.
- 특히 SVM, 로지스틱 회귀, KNN과 같은 알고리즘에 유리합니다.
예시 코드
standard_scaler = StandardScaler( )
x_train_standard = x_train.copy()
x_test_standard = x_test.copy()
columns_to_scale = x_train.columns
x_train_standard[ columns_to_scale ] = standard_scaler.fit_transform(x_train_standard[ columns_to_scale ])
x_test_standard[ columns_to_scale ] = standard_scaler.transform(x_test_standard[ columns_to_scale ])
정규화 (Normalization)
정규화는 데이터를 특정 범위(주로 0과 1 사이)로 조정하는 방법입니다. 최소-최대 정규화(Min-Max Normalization)가 대표적입니다. 정규화는 다음 공식을 사용합니다:

이는 데이터 x를 최소값 X_min과 최대값 X_max 사이의 범위로 조정하여 0과 1 사이의 값으로 변환합니다.
장점
- 모든 데이터가 동일한 범위 내에 있어 계산이 용이해지고, 특히 신경망이나 거리 기반 알고리즘(KNN, K-means 등)에 유리합니다.
예시 코드
minmax_scaler = MinMaxScaler( )
x_train_minmax = x_train.copy()
x_test_minmax = x_test.copy()
columns_to_scale = x_train.columns
x_train_minmax[ columns_to_scale ] = minmax_scaler.fit_transform(x_train_minmax[ columns_to_scale ])
x_test_minmax[ columns_to_scale ] = minmax_scaler.transform(x_test_minmax[ columns_to_scale ])'인공지능&머신러닝' 카테고리의 다른 글
| [머신러닝]서포트벡터머신(SVM,Support Vector Machine)원리 및 코드 예시 (0) | 2024.06.24 |
|---|---|
| [머신러닝]K-최근접 이웃(KNN모델)원리 및 코드 예시 (0) | 2024.06.24 |
| [머신러닝]결정트리(Decision Tree)원리 및 코드 예시 (0) | 2024.06.24 |
| [머신러닝]나이브 베이즈(Naive Bayes)원리와 코드 예시 (0) | 2024.06.24 |
| 혼동행렬(Confusion matrix) / 정확도 / 정밀도 / 재현율 / F1-score (0) | 2024.06.10 |