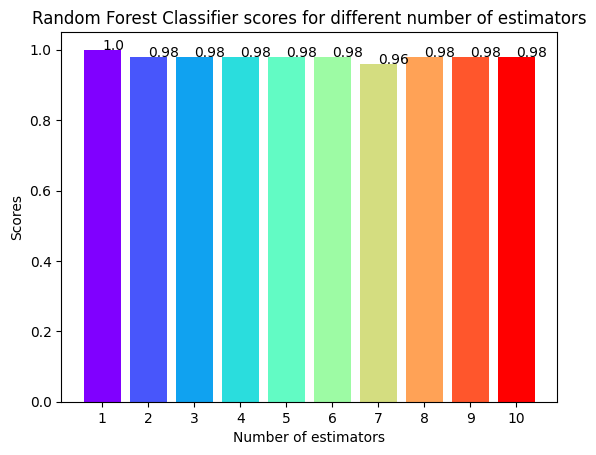
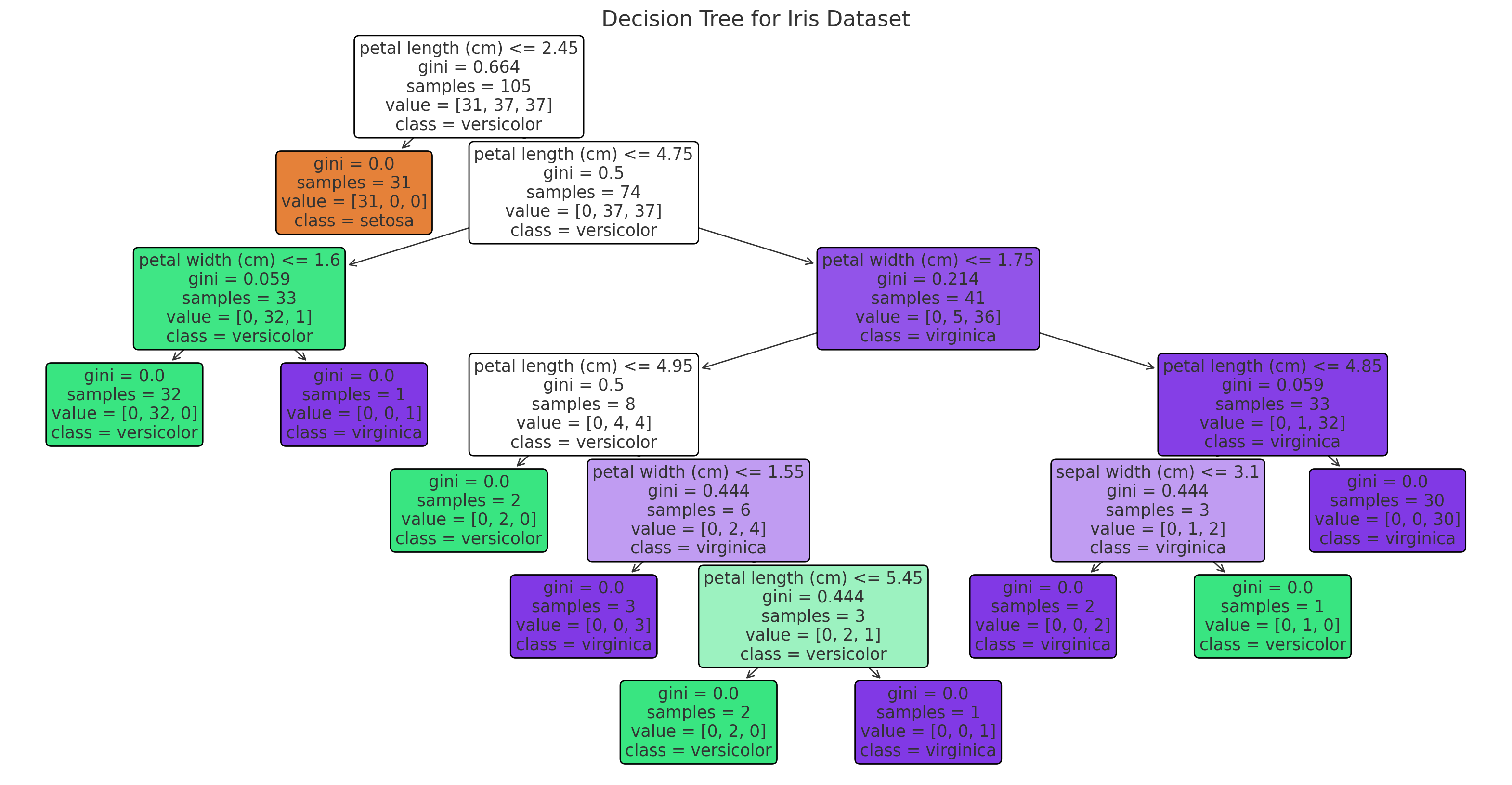
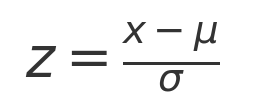앙상블(Ensemble)은 기계 학습에서 여러 개의 모델을 결합하여 하나의 강력한 모델을 구성하는 기법을 말합니다. 각 개별 모델의 예측을 종합함으로써 개별 모델보다 더 나은 예측 성능을 달성할 수 있습니다. 앙상블은 단일 모델보다 더욱 정확하고 안정적인 예측을 제공할 수 있습니다. 주요 개념개별 모델의 다양성 확보: 앙상블은 다양한 방법을 사용하여 여러 개의 개별 모델을 생성합니다. 이들 모델은 독립적으로 학습하거나 서로 다른 학습 데이터를 사용하여 학습될 수 있습니다.결합 방법: 개별 모델의 예측을 결합하는 방법에는 여러 가지가 있습니다. 주로 사용되는 방법으로는 평균화(Averaging), 가중 평균화(Weighted Averaging), 투표(Voting), 스태킹(Stacking) 등이 있습니다..