랜덤 포레스트(Random Forest)는 앙상블 학습 방법 중 하나로, 여러 개의 결정 트리(Classification Trees)를 구성하여 강력한 분류 모델을 만드는 방법입니다. 각 결정 트리는 데이터의 부분 집합을 기반으로 독립적으로 학습하며, 그 결과를 결합하여 최종 예측을 수행합니다.
주요 개념
- 앙상블 학습(Ensemble Learning): Random Forest는 여러 개의 모델을 결합하여 더 강력하고 안정적인 예측을 하려는 앙상블 학습의 한 방법입니다. 각 결정 트리는 서로 다른 데이터 부분 집합에서 학습하고, 그들의 예측을 종합하여 최종 예측을 수행합니다.
- 결정 트리(Decision Tree): Random Forest는 기본적으로 결정 트리를 사용합니다. 결정 트리는 데이터를 분할하여 여러 노드로 구성된 트리 형태의 모델을 생성하며, 각 노드는 데이터를 특정 기준에 따라 분할합니다.
- 랜덤화(Randomization):
- 부트스트랩 샘플링(Bootstrap Sampling): 각 트리는 원본 데이터에서 랜덤하게 선택된 부분 집합으로 학습합니다. 이는 데이터의 다양성을 유지하고, 과적합을 줄이는 데 도움을 줍니다.
- 특성 랜덤화(Feature Randomization): 각 노드에서 분할할 때, 랜덤하게 선택된 특성들 중에서 최적의 분할을 찾습니다. 이는 다양한 특성의 중요성을 반영하고, 모델의 다양성을 증가시킵니다.
- 결합 방법(Combination): 각 결정 트리의 예측을 종합하여 최종 예측을 수행합니다. 분류 문제에서는 각 트리의 클래스 예측 중 가장 많이 선택된 클래스를 선택하거나, 확률을 평균하여 확률 예측을 제공합니다.
작동 원리
Random Forest는 다음과 같은 절차로 작동합니다.
- 트리 구성: 주어진 데이터에서 랜덤하게 부트스트랩 샘플을 선택하여 여러 개의 결정 트리를 독립적으로 학습시킵니다.
- 트리 학습: 각 트리는 랜덤하게 선택된 특성들을 기반으로 노드를 분할하며, 정보 이득이 최대화되는 방향으로 분할 기준을 결정합니다.
- 예측: 새로운 데이터가 주어졌을 때, 각 트리의 예측을 종합하여 최종 예측을 수행합니다.
특징
- 기반이 되는 의사 결정 트리가 단순해서 훈련과 예측이 매우 빠르다.
- 트리들이 완전히 독립적이기 때문에 학습과 예측 모두 병렬처리가 가능하다.
예제 코드
rf_scores = []
estimators = range(1,11)
for i in estimators:
rf_classifier = RandomForestClassifier(n_estimators=i, random_state=0 )
rf_classifier.fit(x_train, y_train )
rf_scores.append(rf_classifier.score(x_test, y_test))- 시각화
colors = rainbow(np.linspace(0, 1, len(estimators)))
plt.bar(range(len(estimators)), rf_scores, color = colors, width = 0.8)
for i in range(len(estimators)):
plt.text(i, rf_scores[i], rf_scores[i])
plt.xticks(ticks = range(len(estimators)),
labels = estimators)
plt.xlabel('Number of estimators')
plt.ylabel('Scores')
plt.title('Random Forest Classifier scores for different number of estimators')
plt.show()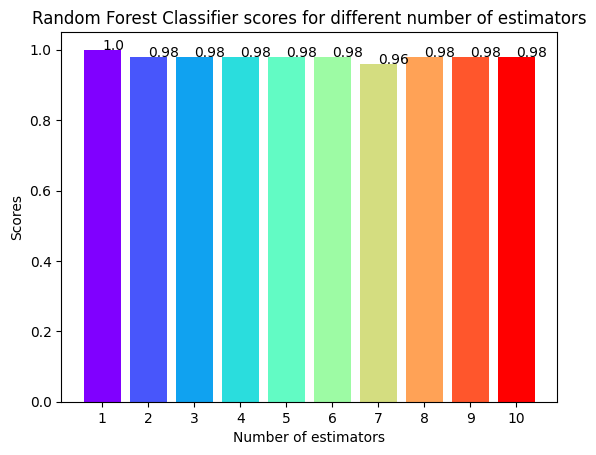
- 성능평가
max_idx = np.argmax(rf_scores)
print("The score for Random Forest Classifier is {}% with {} estimators.".format(rf_scores[max_idx]*100,
estimators[max_idx]))'인공지능&머신러닝' 카테고리의 다른 글
| [머신러닝]앙상블(Ensemble) 원리 및 코드 예시 (0) | 2024.06.24 |
|---|---|
| [머신러닝]서포트벡터머신(SVM,Support Vector Machine)원리 및 코드 예시 (0) | 2024.06.24 |
| [머신러닝]K-최근접 이웃(KNN모델)원리 및 코드 예시 (0) | 2024.06.24 |
| [데이터 전처리]데이터 스케일링(Data Scaling): (0) | 2024.06.24 |
| [머신러닝]결정트리(Decision Tree)원리 및 코드 예시 (0) | 2024.06.24 |